Is it safe to give up your subscription to Spotify yet? Let's find out.
Preface
Unlike my previous posts, this article requires a good understanding of 6502 Assembly. If you are still wasting your time with the likes of Java, Python, or whatever they told you it is in fashion in 2018, you might want to reconsider your priorities: it's not too late to learn this magnificent programming language. You might even land a job at NASA. You will thank me later.
As readers of these pages know, I've always been obsessed with audio and video compression for humble machines. My game Planet Golf for the Commodore 64 even includes Full Motion Video running from a floppy disk. The problem with this stuff, though, is that, as much as it's interesting to see these experiments run on such a limited piece of HW, and as much as it feels like an achievement to the programmer, that doesn't change their gimmicky nature. In other words, let's be honest, no person in their right frame of mind would waste a second of their time listening to those scratchy sounds, unless deafened by unconditional love for the machine. Spoiled as we are with high quality sound coming from all kinds of devices around us, poor Commodore 64 cannot be our to-go solution for our aural pleasure.
Or can it?
Mission
To build a C64 software player that can play a whole song at 48Khz (higher frequency than CDs' 44.1Khz) using a stock Commodore 64 and a regular ROM cartridge, which is your typical 80s setup.
Now, there are all kinds of devilish pieces of hardware available for your Commodore 64 nowadays, such as 16Mb RAM Expansion Units, or even mp3 hardware players. Of course, this stuff was not around in the 80s, and it therefore does not appeal to purists. In other words, any reliance on these monstrosities would get me disqualified. You might as well run a marathon riding a motorbike.
The largest "legitimate" ROM Cartridges are those that Ocean used for their games. You can store a whopping one megabyte of data onto them. We are going to need all of it!
In Numbers
So, we are playing 8-bit samples at 48Khz from one megabyte of storage, minus few Kbytes for the actual player code. This leaves us with 48Kb to encode one second of uncompressed audio, and means that the whole cartridge can barely contain 20 seconds of audio. Which means that we must implement some form of compression, ideally at least 4:1 to get close to 1m30 sec of audio.
Commodore 64's CPU runs at roughly 1Mhz. This means that, if we want to play 48000 samples per second, we only have about 100000/48000 = 21 CPU clock cycles per sample.
Now, how does playing a sample occur? C64 can play 8-bit samples, using a trick that has been recently invented by Pex Tufvesson. The oscillators must be configured and locked in a certain way, and after that, writing to the volume register generates a shift in the voltage, which in turn makes the sample audible. Unfortunately, unlike the 4-bit playing technique, this shift is not linear with the sample value. Therefore, one needs to read an 8-bit entry from memory, use that entry to fetch an amplitude value from a LUT, and finally write this amplitude value into the SID volume register, $d418. Assuming that our first sample sits at $8400, and that our 256 entries lookup table sits at $1000, this is what we need to do to play the first sample.
ldx $8400
lda $1000,x
sta $d418
This means that whatever form of compression we come up with, it must be extremely efficient and snappy. Possibly, again, a simple look up from a table.
Vector Quantization springs to mind: we need a set of 4-byte codebooks so that, splitting the original waveform in blocks of 4 adjacent samples, each of these blocks can be represented by an index in the codebook table, and ideally the number of codebooks should be 256, so that we can use a single byte as an index. This yields the 4:1 compression ratio that we are seeking, but to use only 256 codebooks for a whole song and maintain a good quality is wishful thinking. That is why most vector quantization based compression codecs need a dynamic codebook set. As the playing progresses, least recently used codebooks are discarded and replaced with fresher ones encoded in the actual bitstream. With so few clock cycles available, though, we can't even think of implementing such a complex scheme, so our approach will be to periodically replace all of the codebooks.
Although not optimal from the point of view of the quality, this solution actually plays very well along the limitations of the cartridge, which is operated by means of bank switching. One could think of switching bank and switching codebooks at the same time.
Each bank consists of 16Kbytes. If we use 256 4-byte codebooks for each of these banks, we "waste" 1Kb for the codebooks set and are left with 15 Kb to store 15*1024 entries which will translate to 15*1024*4 samples. The added footprint of the codebooks reduces the compression ratio from 4:1 to 3.75:1, but we can live with that.
We'll see later what the encoder looks like, although there'll be no huge surprises.
The play routine
The cartridge layout consists of 64 banks of 16 Kbytes each. Within the commodore 64 address space, each of these banks can be mapped to $8000-$BFFF. By writing values from $00 to $3f to cart register $de00 we can switch-in one of the 64 banks. We'll place our set of codebooks for each bank at the beginning of the dataset, in an interlaced way. So the first byte of the first codebook will be at $8000, the second will be at $8100 and so on. The n-th byte of the m-th codebook will be at $8000 + n*$100 + m
So our player will look like:
For (bank = $00; bank <= $3F; bank++)
{
bank->$de00 //select bank
For (i = $8400; I < $c000; i++)
{
Id = mem[i]
Sample0 = mem[$8000 + Id]
SYNC()
PLAY(Sample0) //store value to $d418
Sample1 = mem[$8100 + Id]
SYNC()
PLAY(Sample1) //store value to $d418
Sample2 = mem[$8200 + Id]
SYNC()
PLAY(Sample2) //store value to $d418
Sample3 = mem[$8300 + Id]
SYNC()
PLAY(Sample3) //store value to $d418
}
}
The SYNC() pseudo function is the key here. The actual playing, which means writing the sample value to register $d418, must occur exactly every 21 clock cycles. In fact, it's not that important that the actual frequency of 48000Hz is precisely matched (few Hz more or less won't make that much of a difference), what really counts is that the same frequency is maintained. What would happen if we played one of those 4 samples in the loop, say, 20 cycles after the previous one? That would add an ear-piercing high-frequency phase noise distortion to the sample. This kind of jittering is not a problem at very low frequencies (we'll use that to our advantage), but at 12Khz (1 in every 4 samples) it will seriously affect the quality of the output.
Now that we know all the constraints, let's take a look at a possible first version of the player. Which plays an entire bank from the cartridge.
sample: ldx $8400 ldy $8000,x lda sidtable,y sta $d418 nop //wastes 2 cycles nop //wastes 2 cycles nop //wastes 2 cycles bit $ea //wastes 3 cyclesldy $8100,xlda sidtable,ysta $d418nop //wastes 2 cyclesnop //wastes 2 cyclesnop //wastes 2 cyclesbit $ea //wastes 3 cyclesldy $8200,xlda sidtable,ysta $d418nop //wastes 2 cyclesnop //wastes 2 cyclesnop //wastes 2 cyclesbit $ea //wastes 3 cyclesldy $8300,x //4 cyclessidtable,y //4 cyclessta $d418 //4 cyclesinc sample + 1 //6 cycles bne sample //2 cycles if jump does not occur, //3 otherwise inc sample + 2 lda sample + 2 cmp #$c0 bne sample
Now - this does what we need in terms of decoding and playing the data, but timing is completely screwed up. If you check the "distance" between two consecutive operations STA $d418, for the first three samples it takes exactly 21 cycles, but problems arise when you get to the last block. Altering the sample read address and looping back takes a variable amount of cycles. In case we are not crossing the page boundary, when the bne sample instruction actually jumps, we are very lucky, because the loop takes exactly 21 cycles until the next STA $d418. On the other hand, if the jump does not occur, the number of cycles until the next STA $d418 becomes 35!
One could say that this only happens once every 256 code entries, so once every 1024 samples, and that is not a big deal, after all. Unfortunately, at these high frequencies this means that the distortion would still be quite noticeable. We must get rid of those final 14 cycles. Since every 16Kb cart block only has 15Kb of actual code data, which is 60 pages, one could think of unrolling the external loop. Let's give it a try:
For (i=0; i<60; i++) { sample: ldx $8400 + i*$100 ldy $8000,x lda sidtable,y sta $d418 nop //wastes 2 cycles nop //wastes 2 cycles nop //wastes 2 cycles bit $ea //wastes 3 cycles ldy $8100,x lda sidtable,y sta $d418 nop //wastes 2 cycles nop //wastes 2 cycles nop //wastes 2 cycles bit $ea //wastes 3 cycles ldy $8200,x lda sidtable,y sta $d418 nop //wastes 2 cyclesnop //wastes 2 cyclesnop //wastes 2 cyclesbit $ea //wastes 3 cycles ldy $8300,x //4 cycles lda sidtable,y //4 cycles sta $d418 //4 cycles inc sample + 1 //6 cycles bne sample //2 cycles if jump does not occur, //3 otherwise }
That is starting to look better: each sample plays exactly after 21 cycles, like in the previous version. There are still a couple of issues, though. When the last sample is played, the bne sample instruction only takes 2 cycles, so the following sample is played after 20 cycles, not 21. One cycle less every 1024 samples is not as bad as 14 more, but still not acceptable. More than this, though, there's a serious problem with loop unrolling on the C64: When branches occur across pages, they take one cycle more! Some of these 60 play routines will certainly end up crossing page boundaries, hence screwing up the timing once again. What we can do is to align the loops at the page boundary, but this would add gaps in between the play routines. These gaps must be jumped over with a jmp instruction, which in turn adds another 3 cycles, once again screwing up the timing. In fact, if you take a look at what happens to the end of the first play routine, you'll see something like this:
sta $d418 //4 cycles
inc sample + 1 //6 cycles
bne sample //2 cycles if jump does not occur,
//3 otherwise
jmp nextblock //3 cycles
.align sample: ldx $8400 + i*$100 //4 cycles
ldy $8000,x //4 cycles
lda sidtable,y //4 cycles
sta $d418 //4 cycles
27 cycles!
It's a bit like solving a Sudoku puzzle, isn't it? And this is getting a bit boring too, so, without further ado, I present you with the final version:
.for (var i=0; i<60; i++) { l: nop sample: ldx $8400 + i*$100 ldy $8000,x lda sidtable,y sta$d418inc sample +1 bit $ea ldy $8100,x lda sidtable,y sta$d418inc $d020 bit $ea ldy $8200,x lda sidtable,y sta$d418bit $ea //3 nop //5 ldy $8300,x //9 lda sidtable,y //13 ldy sample + 1 //17 sta$d418//21 bne l //2 cycles. 3 cycles if jumps //to the first nop jmp nextblock+1 //3
.align 64 //the whole code is less than 64 bytes
//so aligning to 64 should fit 4 blocks in one page,
//while still preventing cross-page branching nextblock:
//there'll be a nop here,
// but it will not be executed at the first run
}
If you check all the possible "paths" within this code, you'll find out that writes to $d418 always occur 21 clock cycles apart, no matter the flow. The secret was to "spread" all of the loop handling logic across the 4 sample play sections in each loop, leveraging those sync dummy operations to do something useful rather than active wait, thus saving precious cycles in the last block to accommodate the jmp to the next page play routine.
Now each of the 1024*60 samples played from a cartridge bank plays exactly 21 cycles after the previous one, and we even managed to squeeze in an inc $d020, to show some raster effect on the screen.
Now I hear you say, there must still be some code to switch banks, and that will waste precious clock cycles, adding some delay.
You are right, but we don't have to do anything about that. We are talking about an off-sync every 60000 sample, that is 1.28 seconds: a phase noise at a frequency that is lower than 1hz, which is not audible.
Job done.
Songs
1:30 might sound like a tight limitation, but there are still plenty of songs that come in at less than 90 seconds. I ended up choosing Elvis Costello's "Welcome to the Working Week", from his debut album My Aim is True, and my favourite piece of music from my favourite progressive band: Jethro Tull's "Cheap Day Return", from the seminal record Aqualung
Both Aqualung and My Aim is True are available in digitally remastered edition in 96khz 24bit lossless format: plenty of quality to start from.
The encoder
Vector Quantization is an easy approach to achieve decent compression with minimal impact on the decoder performance. In fact, in the setup I've used, it only takes a single lookup from the codebook table to fetch a sample. In order to obtain about X:1 compression, one needs to split a given PCM vector of n samples into n/x vectors of x consecutive samples, with x=4 in our case. This would be the input to a round of clustering, typically K-means, with K=256 in our case being the number of codebooks we want to compute.
Since K is a power of 2, we can also use LBG, which, in this case, performs slightly better.
But more than the clustering algorithm, what really makes the difference here is the way we can prepare the data. Rather than using the original PCM waveform, I worked with a delta representation of the square root of each sample.
Let's say that A is our waveform with -1.0<ai<1.0 for each sample, our clustering pass runs instead on the pseudo waveform B which is defined as
bi = sign(ai)*sqrt(|ai|) – sign(ai-1)*sqrt(|ai-1|)
bi = sign(ai)*sqrt(|ai|) – sign(ai-1)*sqrt(|ai-1|)
The square root works as a poor man's amplification filter for high-frequency parts or for fricative sounds that typically come with low amplitude. The clustering pass would otherwise zero these finer details. The use of differential pcm, instead, brings in the idea that transitions, more than absolute values, are what we actually hear in a waveform.
Of course the set of codebooks that we obtain from this clustering pass is not representative of the original waveform A, only the clusters are. Therefore, we must recompute the centroids of the clusters using the actual vectors from A.
Higher values of K can be used, which lead to higher compression rates at the cost of quality.
K=4, as used in the demo, brings in a minimal degradation. I've experimented with higher values and K=8 is still kind of acceptable, and allows for almost 3 minutes of music to fit on a cartridge, but of course much depends on the type of content that we are encoding.
In the following picture you can see, in order, 500msec of the original, uncompressed audio, the differential on the squared signal used as input for the encoder, and the codebook-reconstructed 8-bit waveform, which is what the C64 plays
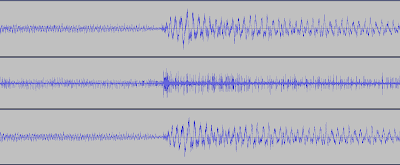
In the following picture you can see, in order, 500msec of the original, uncompressed audio, the differential on the squared signal used as input for the encoder, and the codebook-reconstructed 8-bit waveform, which is what the C64 plays
Further Development
I got a lot of "Why don't you use a 16Mb REU?" As I said, I'm not really keen on using HW that is not true to the spirit of the 80s. REUs (Ram Expansion Units) did exist in the 80s, but only came in 128, 256 and 512kb cuts. 16Mb REUs are just a modern thing and, although one could in theory put an entire record onto a 16Mb REU with this encoder, where would the fun be? One advantage that REUs have over a cartridge, though, is that, being RAM, you can actually write it. This means that the amplitude values for a specific SID chip could be hardcoded to the codebooks before we play the song, and the lookup from the sidtable would no longer be needed at playtime, freeing 4 precious clock cycles per sample, and thus paving the way to even higher sampling frequencies, if that even makes sense. How about a 64Khz compressed-audio player? Not sure the difference would be audible and that it would make much sense, but again nothing here makes sense in first place, so why not?
The second most asked question is, "Will you release the encoder"? Well, the encoder is just a bunch of Python scripts at the moment, and it's described in this very blog post, so in theory anyone can recreate it now, but I guess it would still be nice to release a user-friendly application for those who don't want to mess around with scikit-learn. If I am not distracted by even more ridiculous projects, that is what I am doing next.
Reception
The demo was well-received and got quite some attention. I shared the YouTube previews right before I uploaded the actual demo to CSDB, just because that requires a bit more time. Still, those few minutes that passed between the two actions caused a lot of people to shout "fake!", despite the fact that I had stated that the download would have been available shortly. I guess that "it sounds so good I think it's fake" counts as the most flattering of the compliments!
The demo is currently number 9 in CSDB's top C64 demos of all time, which, you could say, is a bit of an overestimation of the actual value of the production. And I totally agree.
The fact is that the demo doesn't really break any new ground: Vector Quantization has been used in few productions already (although I'm not sure about the combination with DPCM), and high-frequency digi playing has been a thing for quite some time, mostly thanks to the oustanding work of Pex Tufvesson. I guess that doing the two things together, on a proper song, rather than a second or two of speech, was a low hanging fruit that someone had to reap at some point. I was happy to do it, but the real innovators are people like Pex.
Appendix
I also developed a 3-byte codebook version of the player, so that I could use a less destructive compression for songs that do not make it past the 60-second mark. This was a bit trickier because there are fewer cycles available in the main loop to "spread" the instructions controlling the loop itself. At some point, I needed to add 1 cycle to the last playing write, which is not all that easy because no instruction takes less than 2 cycles, so you can only add 2. I ended up slowing down the read from sidtable just for that single write, which can be done using the y indirect addressing mode.
The "Mazinger Z" song, encoded with this technique, really sounds as good as the original.
.for (var i=0; i<61; i++) { l: nop sample: ldx $8300 + i*$100 ldy $8000,x lda sidtable,y sta $d418 inc sample +1 bit $ea ldy $8100,x lda sidtable,y sta$d418sty $d020 ldy $8200,x lda ($fb),y //like lda sidtable,y but a cycle more ldy sample + 1 sta$d418bne l jmp nextblock+1 .align 64 nextblock: }